
Please note that none of these are from official statements. If anyone wants to provide me with more accurate information on this, or better yet, official statements from the parties concerned, please send me a message and I will gladly incorporate it into the article. My objective here is to provide lessons to the IT and business community so that we can hopefully avoid the all-too-often costly mistakes of IT projects in the future.
The Issues
1. Rip and Replace
Jollibee had originally been using an Oracle product for managing its supply chain - including deliveries of supplies to stores. Because of a dispute with Oracle, Jollibee decided to move its entire supply chain over to Oracle’s rival in this space, SAP.Now, supply chain software aren’t just out-of-the-box products that you can just install and run. These need to be customized heavily in order to fit a company’s business processes, which usually takes months if not over a year of programming and configuration just to get started. The Oracle system had been running in Jollibee for years, and most certainly had a huge amount of complex programming and configuration from continuous modifications over time. These programs and configurations would have had a lot of fragile interrelationships between them, that made it a huge and risky task to migrate over to the SAP system.
If you check out the banking industry, you'll find that all over the world, many banks are still using some software that was written in the 70's and 80's. Banks were some of the earliest adopters of IT, and so they have learned early on the risk and cost of system migration. This is why they choose to keep running old systems, rather than run the risk of a potentially costly migration.
2. Staffing and Expertise
The project was outsourced to a large multinational IT service provider. Upon my interviews with members of the Philippine SAP community, they expressed doubt that the Philippine office of the service provider had a sizable local SAP team, if any. They have never heard of that vendor taking on Philippine projects using SAP before, which is why they concluded that the vendor did not have a significant local SAP practice. |
| Hiring a large team quickly can lead to problems. |
Assembling a large team of outsiders quickly is troublesome. They have not worked under a common methodology and culture. They don't have a common understanding of standards and processes. Any leaders in the group would be overwhelmed from the tasks of understanding the client's business and designing solutions for the client's requirements, working with other leaders to agree to common standards and processes, and then organizing and training teams to adhere to those common standards and processes, and then explaining client requirements and overseeing the quality of work.
3. Schedule and Size
This is a half-a-billion-peso project, yet it seems that the project is only operating schedule of just a little over a year, based on when the recruitment activity started, and when the production issue broke out. Just to give this some perspective, many of the projects I've seen costing just 1/20 of this one usually have a two-year timetables. I'd expect that a project of this size would require three to five years to properly implement, from inception to transition.Maybe this was just a first phase, but unfortunately for Jollibee it has already been a costly first phase. Let's hope some methodology changes have already taken place to avoid costly mistakes in the future.
4. Testing
Ok, my notes here are not specifically about this project, but about ERP projects in general. As one of my friends pointed out, "You'd be surprised at what passes for unit / functional / integration testing in Oracle and SAP projects."Granted, testing is still a terrible area even in Java or .Net projects, but the practices have slowly been gaining ground and maturity over the last ten years. Successful projects often plan and implement tests from the beginning of the project and throughout, not just at the end, with majority of the tests automated. Testing is elevated to a core part of part of the project, not just auxiliary to programming.
5. Big Bang Deployment
During a migration, an organization should keep the old system live so they can roll back to it when problems occur. Notice I said when problems occur, not if. In all my years in IT, I have never heard of a project where no defects were found after deployment. Production issues should be expected. The old system should be kept live so that the business has something to use while the defects in the new system are being fixed.This other blog post discusses how Jollibee, in a previous and smaller system upgrade several years ago, had to resort to manual methods to keep the business going. Manual backup is better than no backup at all, but even manual backup shouldn't be needed if you keep the old system live.
Recommendations
1. Start Small
I've been in the situation where I have been asked by existing clients or potential clients to accept large fixed-scope projects, often on compressed schedules. In such situations, we usually respond by proposing only a smaller-scoped project, one that can be accomplished in around six months, by a team of five people or less. The only exception is if the large project is similar to a project we've done before, for the same client.This is an extremely risky move on our part, since normally, clients are deadset on a large scope, and will only consider vendors that meet the complete scope. However, we do this because it is in the best interest of the client and us as the vendor.
 |
| Start with a small project but with a seasoned team. |
A small initial project would allow the clients to better understand what they really need, and then specify succeeding scope based on something they can see and use. This is similar to the Singaporean government's "Call for Collaboration" approach, where they invite multiple vendors to build paid prototypes in response to specific problems, which becomes the basis for the full project scope.
Second, it allows the vendor to field a seasoned team. Instead of scrambling to staff a large project, the vendor can source existing people within the company, led by one or more senior people, and having a common methodology. This allows the team to focus on the project concerns instead of having to deal with culture and process issues.
Third, scaling becomes easier later on. After the first project with a small seasoned team, both client and vendor learn about how each other works and how to best work with each other. This allows them to take on larger projects together in an efficient manner. The members of the initial team can be the seed members of new teams, to take on succeeding projects. Those that participated on the first project on both sides can pass on their learnings to others to improve the chances of success of succeeding projects.
2. Testing is Core & Automated
The approach of Test-Driven Development has its origins in 1999, and since then the open-source community has produced a rich set of tools to deal with the various aspects of test specification and automation - from functional testing, to user-interface, to data and integration, to performance.The most effective teams have testing as part of the core of their methodology. Teams start the project by defining tests, and then define and run tests throughout the project, not just towards then end. Testing is not relegated to just "testers" or QA personnel, but is an activity done by all practices in their own ways - developers, for example, build numerous automated tests around each significant unit of logic, modeling various scenarios.
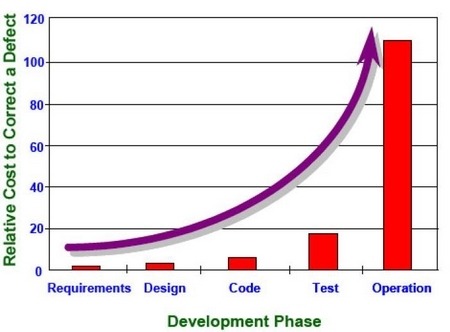 |
| The cost of defects are more expensive if you find them later. |
Let me repeat this fact - defects are cheaper to find and fix if they are found sooner rather than later. Certainly, the defects in the current Jollibee project would have been cheaper had they been found during development, rather than during production, where they are now costing Jollibee millions of pesos a day.
After the system is built, it would naturally go through further enhancements and modifications. These changes can introduce defects. However, the robust suite of automated tests that were created with the system would improve the chances of catching these defects, making it safer and cheaper to maintain the system in the future.
By the way, please note that I'm not advocated automated user interface (UI) testing - where a manual tester's actions are recorded and played back. UI tests are very difficult to maintain since UIs change a lot. What I'm advocating are Unit Tests, Acceptance Tests ("Executable Requirements") and Performance Tests.
Unit Tests are the fine-grained tests that assert code at the method level. Frameworks include JUnit for Java, MSTest for .NET, ABAPUnit for SAP ABAP, and utPLSQL for Oracle PL/SQL. However, before being able to do Unit Testing effectively, the code has to be written in a testable way. The prerequisite, therefore, to using these frameworks is a strong background in Object-Oriented Design.
Acceptance Tests are "Executable Requirements". They start with a document on the requirement or use case, but includes a listing of expected inputs and outputs. These requirements are written in a tool that allows execution of these requirements against the system. Tools include Concordion, Robot Framework, Fitnesse and Cucumber. Again, code has to be written in a testable way.
The third set testing tools are for Performance Testing. These replicate the loads that the system will likely be exposed to - such as being hit by multiple concurrent users at the same time. The tool I've used in the past for this is JMeter.
Performance Tests need not be run every day, but Unit Tests and Acceptance Tests should be run each time a change is committed.
3. Continuous Delivery
One of the riskiest things I see organizations do time and time again, is a big cut-over to a new system. They have a big announcement that, "System X will go live by ____!" When that day does come around (usually delayed), it's invariably a mess! People are unable to get their work done with the new system. If they're lucky, the old system is still around for them to fall back to, while the new system undergoes bug-fixing. If they're not lucky, the old system is no longer available either.Compare this to how Google or Facebook roll out their changes. Notice that your GMail or Facebook has new features come out every few weeks or months. If you don't like the feature, there's a button that allows you to rollback to the old way of doing things. This button is Google's and Facebook's way of getting feedback from their users. They roll out the new features to just a partial set of users. If the users opt to rollback, then Facebook and Google know they still need to improve the feature. Then they roll it out again to another set of users. When they hit the point when few users opt to rollback, then they know they've got the feature right and make it a permanent part of their systems.
 |
| Deploy iteratively and incrementally. |
4. Visibility Through Process & Tools
My final piece of advice sort of puts everything together so that clients can monitor the progress of a project, and catch problems earlier rather than later. A good, responsible team provides visibility to its client. And this visibility is provided via concrete evidence, not status reports that can be faked.Regular Demos. A good team can provide their client with working software, as often as every one or two weeks. These aren't PowerPoint presentations. Instead, they're demos of new features to the software that clients can try out and give feedback on.
Test Reports. Automated tests can and should be run multiple times a day, usually using centralized systems called "Continuous Integration Servers". These systems can provide clients several times a day with reports on the various tests, and whether they pass or fail. Some of these tests, known as "Acceptance Tests", are readable by non-technical users, so you can see what behavior is being added to the system, and whether the system already complies with the behavior.
Quality Metrics. Aside from test reports, various tools can be added to the Continuous Integration Server to generate other reports. Among these reports are metrics on quality - For example, in Java there are various tools that can check if the code contains violations of coding standards, or contains logic that is too convoluted, or contains code that often leads to bugs.
Big Visible Charts. If the team works onsite, various charts in the team work area can give the rest of the organization an idea of the progress of the team. Two of the more popular charts are Task Boards and Burndown Charts.
No comments:
Post a Comment